
A common lament among machine learning engineers is that, in general, putting machine learning (ML), deep learning (DL), and AI applications into production is problematic. Many engineers would attest that a large percentage – estimated at 90% – of ML models never see the light of the day in production.
Let’s examine four best practices to prevent these problems. Derived from industry trends, practitioner literature, and codified MLOps best practices, these four best practices will improve the process of deploying models in production.
Also see: Top AI Software
1) Get Your Data Story Sorted
Data is complex and dirty. It’s complex because data varies in form and format: batch or streaming, structured, unstructured, or semi-structured data. It’s dirty because often, data has missing or erroneous values. No deep learning or AI model is valuable without voluminous, cleansed, and feature-engineered data.
You need a robust data store to process the big data needed to build accurate models. A modern data lake stores both structured and unstructured data. A modern data lake has the following data properties:
- Provides ACID transactions so multiple readers and writers can update and read data without contention or conflict, allowing concurrent ETL (extract, transform, and load) jobs and constant inserts and updates.
- Stores data in an open format such as Parquet, JSON, or CSV, allowing popular deep learning frameworks to openly and efficiently access data.
- Holds structured data as tables that can be versioned and adhere to a schema, allowing model reproducibility and accountability.
- Offers fast and searchable access to the various kinds of data (labeled, images, videos, text, etc.), allowing machine learning engineers to fetch the right data sets for the right business problem.
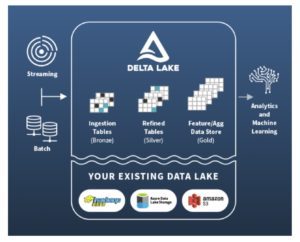
A modern data lake as a data store.
Without a cohesive data store as the canonical reliable and cleansed data source to all your ML models for training and inference, you’ll stumble onto your first “data” pitfall. This is true no matter which deep learning framework you use — which brings us to the next consideration.
Also see: DevOps, Low-Code and RPA: Pros and Cons
2) Use Well-Adopted and Widely Used Frameworks
Just as good data begets good models, so do widely adopted deep learning toolkits and frameworks. No one would dispute among the ML/DL practitioners that PyTorch, PyTorch Lightning, TensorFlow, HuggingFace, Horovod, XGBoost, or MXNet are popular frameworks for building scalable deep learning models. Aside from being widely used, they have become the go-to framework to build sophisticated deep learning and AI applications.
Adopt these frameworks because:
- They have a large supporting community, copious documentation, tutorials, and examples to learn from.
- They support training and inference on modern accelerated hardware (CPUs, GPUs, etc.).
- They are battle-tested in production (used by notable companies).
- They are natively integrated with Ray, an emerging open-source general-purpose framework for building and scaling distributed AI applications.
- They have Python API bindings, a de facto language for deep learning.
- They have integrations with MLflow, KubeFlow, TFX, SageMaker, and Weights & Biases for model provisioning and deploying and orchestrating model pipelines in production.
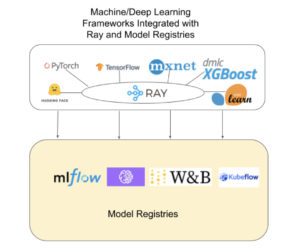
ML/DL Framework integrations with Ray and Model Registries.
Not using the battle-proven frameworks well-integrated with popular open-source tools for model development cycle and management or distributed training at scale is a sure way to stumble onto another pitfall: wrong tools and frameworks. The need for a model development lifecycle leads us to why you want to track model training using a model store.
Also see: Data Mining Techniques
3) Track Model Training with a Model Store
The model development lifecycle paradigm is unlike the general software development lifecycle. The former is iterative, experimental, data and metric-driven. Several factors affect the model’s success in production:
- Are the model’s measured metrics accurate? A model registry will track all the metrics and parameters during training and testing that you can peruse to evaluate.
- Can I use more than one DL framework to obtain the best model? Today’s model registries support multiple frameworks to log models as artifacts for deployments.
- Were the data sources reliable and sufficient in volume to represent a general sample? This is the successful outcome of getting the data story right.
- Can we reproduce the model with the data used for training? The model registry can store meta-data as references to data tables in the data store. Access to the original training data and meta-data allows reproducing a model.
- Can we track a model’s lineage of evolution — from development to deployment — for provenance and accountability? Model registries track versioning of each experiment run so that you can extract an exact version of the trained model with all its input and output parameters and metrics.
Tracking experiments for models and persisting all aspects of its outcome — metrics, parameters, data tables, and artifacts — gives you the confidence to deploy the right and the best model into production. Not having a data-and-metric-driven model for production is another pitfall to avoid. But that’s not enough; observing models’ behavior and performance in production is as important as tracking experiments.
Also see: Data Mining Techniques
4) Observe the Model in Production
Model observability in production is imperative. It’s often an afterthought – but this is at your peril and pitfall. It should be foremost. ML and DL models can degrade or drift over time for a few reasons:
- Data and model concept drift over time: Data is complex and never static. The data with which the model was trained may change over time. For example, a particular image trained for classification or segmentation might have additional features unaccounted for. As a result, the model concept of inference may drift, resulting in errors, drifting away from the ground truth. Such detection of drifts requires retraining and redeploying a model.
- Models’ inferences fail over time: Model predictions fail over time, giving wrong predictions, resulting from the above data drift.
- Systems degrade over a heavy load: Though you account for reliability and scalability as part of your data infrastructure, keeping vigilant health of your infrastructure – especially your dedicated model servers during spikes of heavy traffic – is vital.
Also see: Tech Predictions for 2022: Cloud, Data, Cybersecurity, AI and More
About the Author:
Robert Nishihara is the Co-Founder and CEO of Anyscale. He has a PhD in machine learning and distributed systems.